
I am currently a researcher at ByteDance Seed, focusing on large multimodal model development for speech interaction. I earned Ph.D. degree at Shanghai Jiao Tong University, under the supervision of Prof. Xiaolin Huang. I also spent several wonderful months as a visiting student in the Department of Computer Science and Engineering at The Hong Kong University of Science and Technology, under the guidance of Prof. James Kwok. My research interests include machine learning, reinforcement learning, and optimization, with a particular focus on the efficiency, robustness, and generalization of optimization algorithms in the era of large language models.
I have a solid foundation in data structures and algorithms, and I previously participated in multiple competitive programming contests. I am always open to academic discussions and potential collaborations. Feel free to reach me via email: li.tao@sjtu.edu.cn, or WeChat: nblt1998.
🔥 News
- 2026.01: 🎉🎉 Three papers have been accepted to ICLR 2026, including one Oral presentation: Bi-LoRA for efficiently improving the generalization of LoRA fine-tuning, RAIN-Merging for enhancing instruction following in reasoning models, and DuPO for enabling reliable self-verification via dual optimization. Congratulations to all collaborators!
- 2025.05: 🎉🎉 Our paper “Flat-LoRA: Low-Rank Adaptation over a Flat Loss Landscape” is accepted to ICML 2025. Try it to improve fine-tuning performance with little additional memory and computation efforts!
- 2025.03: 🎉🎉 Our paper “Distraction is All You Need for Multimodal Large Language Model Jailbreaking” is accepted to CVPR 2025 as highlight.
- 2024.09: 🎉🎉 Our paper “Unified Gradient-Based Machine Unlearning with Remain Geometry Enhancement” is accepted to NeurIPS 2024 as spotlight.
- 2024.09: 🎉🎉 Our paper “PromptIntern: Saving Inference Costs by Internalizing Recurrent Prompt during Large Language Model Fine-tuning” is accepted to EMNLP 2024 Findings. Congrats to collaborators!
- 2024.09: 🎉🎉 Our paper “Low-Dimensional Gradient Helps Out-of-Distribution Detection” is accepted to TPAMI 2024.
- 2024.07: 🎉🎉 Our paper “Learning Scalable Model Soup on a Single GPU: An Efficient Subspace Training Strategy” is accepted to ECCV 2024.
- 2024.04: 🎉🎉 Our paper “Online Continual Learning via Logit Adjusted Softmax” is accepted to TMLR 2024.
- 2024.03: 🎉🎉 Our paper “Revisiting Random Weight Perturbation for Efficiently Improving Generalization” is accepted to TMLR 2024. A short version is on NeurIPS Workshops on Optimization for Machine Learning (2023).
- 2024.02: 🎉🎉 Our paper “Friendly Sharpness-Aware Minimization” is accepted to CVPR 2024.
📝 Selected Publications
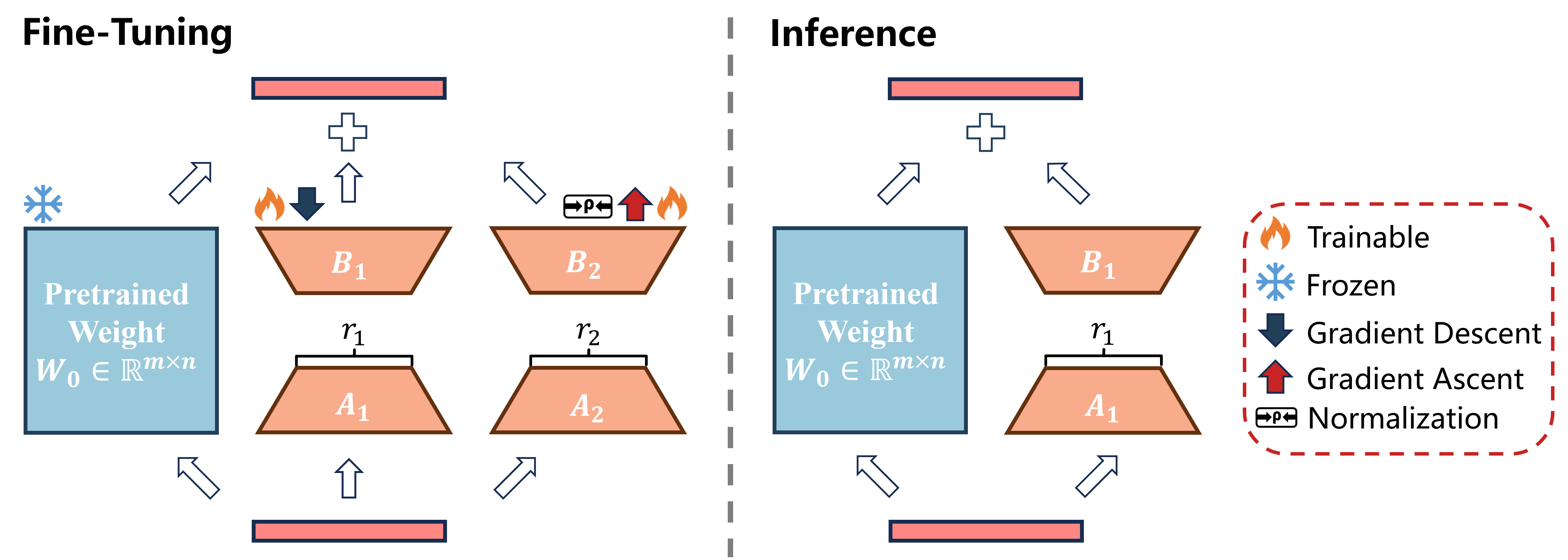
Bi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale Models
Yuhang Liu#, Tao Li#, Zhehao Huang, Zuopeng Yang, Xiaolin Huang
- This work proposes Bi-LoRA, which introduces an auxiliary LoRA module to model the adversarial weight perturbations of SAM. This approach enhances generalization without incurring the doubled computational overhead typically associated with SAM. Extensive experiments across math reasoning, code generation, and dialogue generation tasks demonstrate the significant effectiveness of the proposed method.
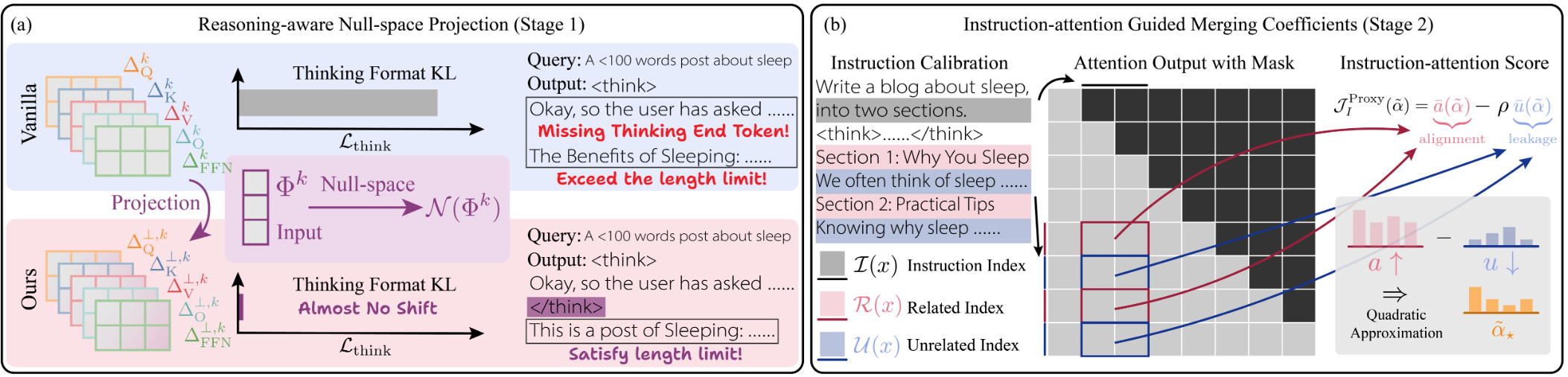
RAIN-Merging: A Gradient-Free Method to Enhance Instruction Following in Large Reasoning Models with Preserved Thinking Format
Zhehao Huang, Yuhang Liu, Baijiong Lin, Yixin Lou, Zhengbao He, Hanling Tian, Tao Li, Xiaolin Huang
- This work proposes Flat-LoRA, which aims to efficiently optimize the sharpness of the loss landscape in the full parameter space for low-rank adaptation by using designed random weight perturbations. Improve in/out-of-domain generalization with little computational and memory overheads!
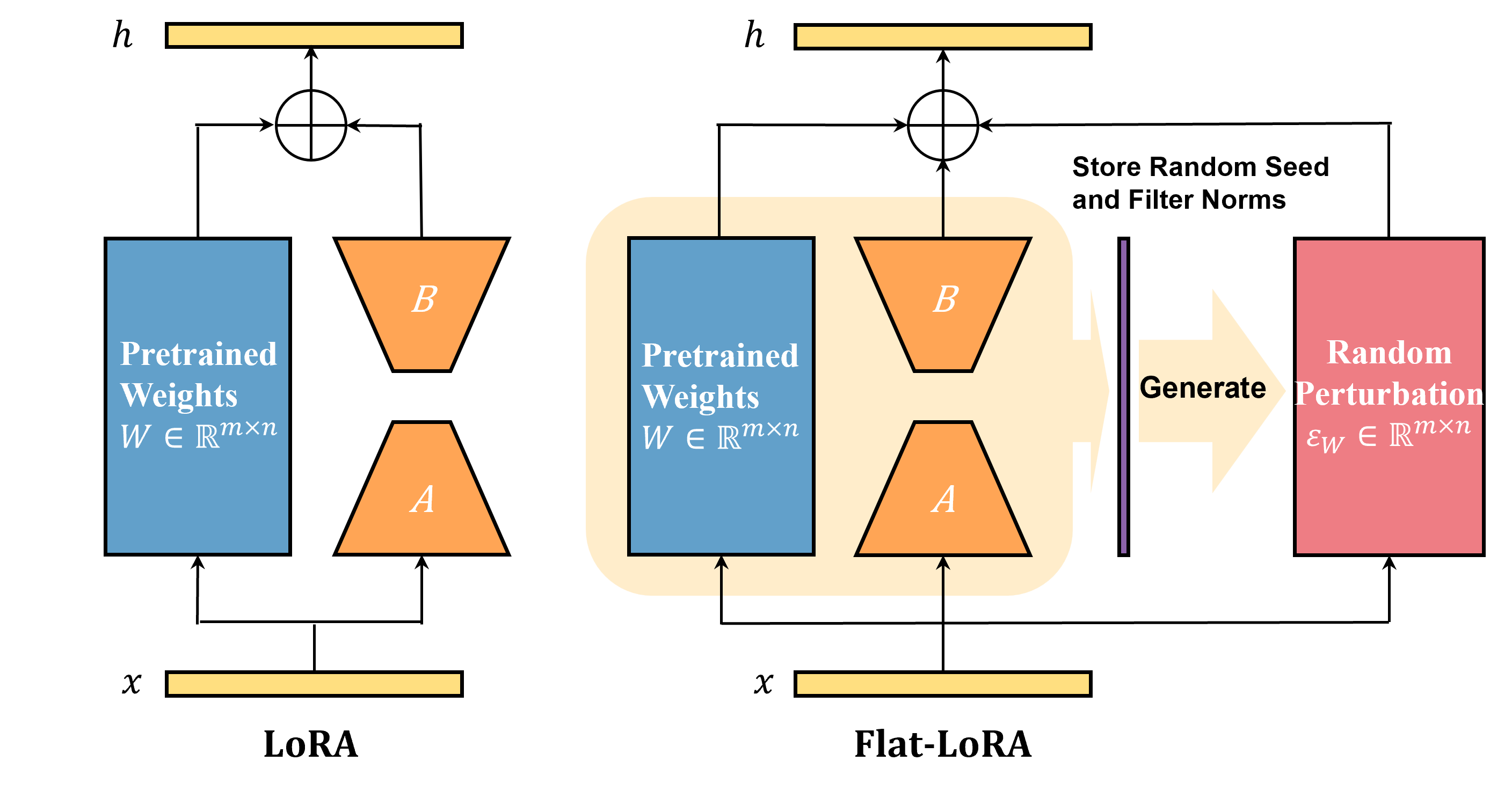
Flat-LoRA: Low-Rank Adaptation over a Flat Loss Landscape
Tao Li#, Zhengbao He#, Yujun Li, Yasheng Wang, Lifeng Shang, Xiaolin Huang
- This work proposes RAIN-Merging, a gradient-free method designed to integrate instruction-following capabilities while strictly preserving the model’s thinking format and reasoning performance. It achieves this by projecting the task vector onto the null space of reasoning features to protect structured thinking, combined with instruction-attention-guided scaling to amplify relevant components. Substantially improve instruction adherence across diverse benchmarks and agent settings without compromising reasoning quality!
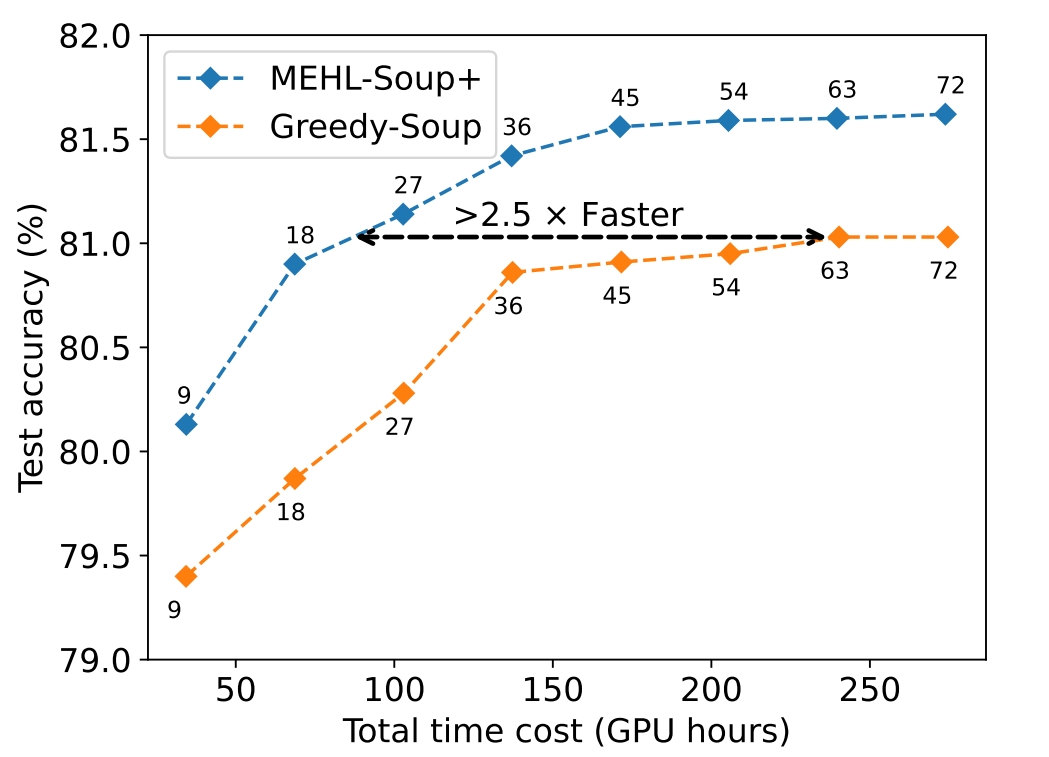
Learning Scalable Model Soup on a Single GPU: An Efficient Subspace Training Strategy
Tao Li#, Weisen Jiang#, Fanghui Liu, Xiaolin Huang, James T. Kwok
- This work proposes a scalable strategy to learning a model soup, tackling the long-existing memory problem and making it easy for practical usage. We show that learning a model soup can bring >2.5x time saving for fine-tuning compared with greedy soup.
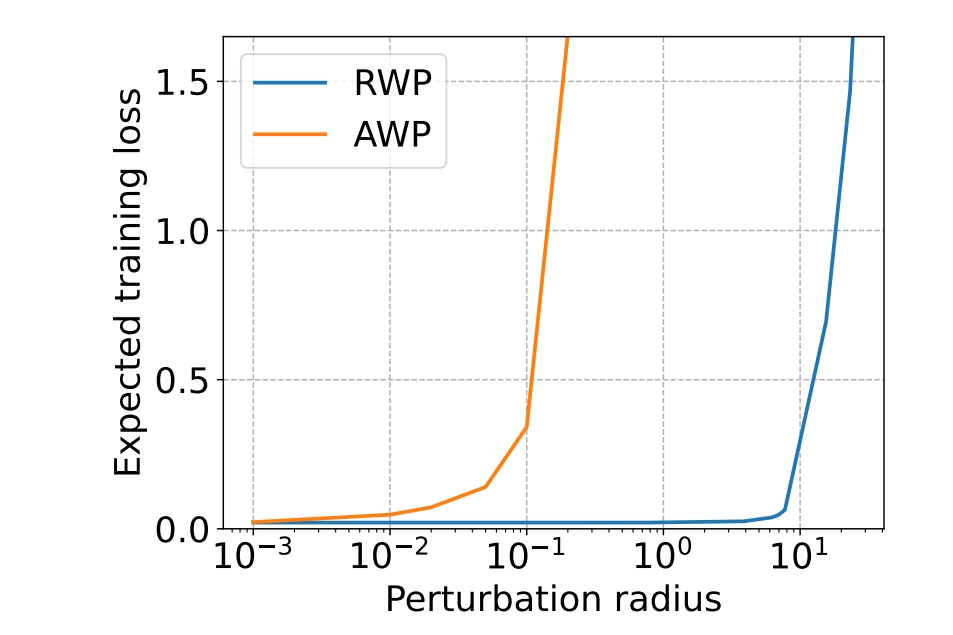
Revisiting Random Weight Perturbation for Efficiently Improving Generalization
Tao Li, Qinghua Tao, Weihao Yan, Yingwen Wu, Zehao Lei, Kun Fang, Mingzhen He, Xiaolin Huang
- This work enhances the generalization performance of random weight perturbation from the perspective of convergence and perturbation generation, and shows that it can achieve more efficient generalization improvement than adversarial weight perturbation in SAM, especially on large-scale problems.
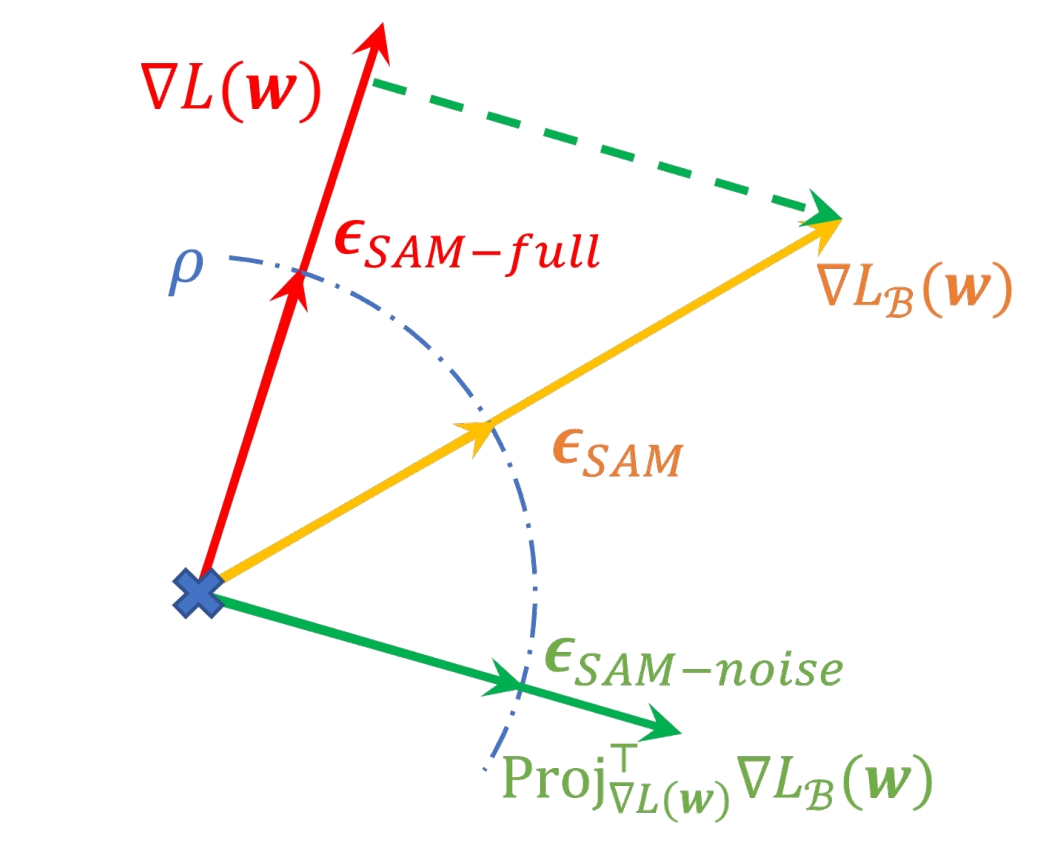
Friendly Sharpness-Aware Minimization
Tao Li, Pan Zhou, Zhengbao He, Xinwen Cheng, Xiaolin Huang
- This work uncovers that the full gradient component in SAM’s adversarial perturbation does not contribute to generalization and, in fact, has undesirable effects. We propose an efficient variant to mitigate these effects and enhance the generalization performance.
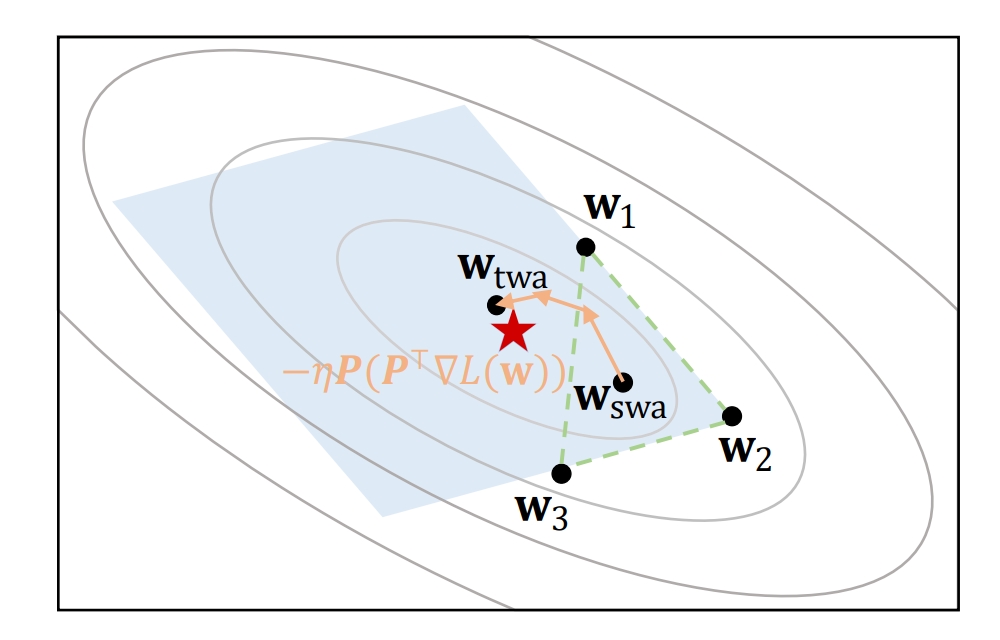
Trainable Weight Averaging: Efficient Training by Optimizing Historical Solutions
Tao Li, Zhehao Huang, Qinghua Tao, Yingwen Wu, Xiaolin Huang
- This work introduces trainable weight averaging to average the historical solutions during the DNN training process to achieve efficient training and better performance.
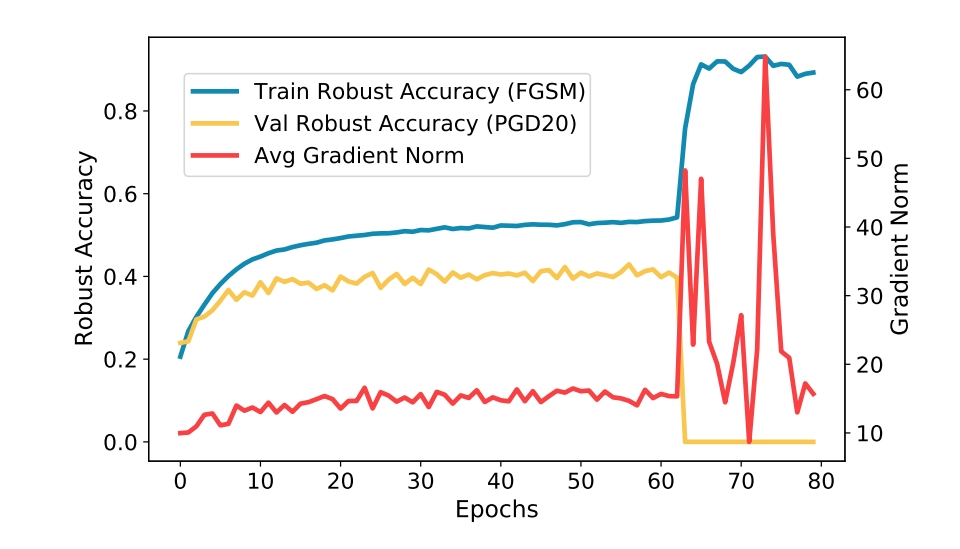
Subspace Adversarial Training
Tao Li, Yingwen Wu, Sizhe Chen, Kun Fang, Xiaolin Huang
- This work proposes subspace training as a method to address the overfitting issues in single and multi-step adversarial training, known as catastrophic and robust overfittings. We achieve efficient and stable single-step adversarial training with comparable robustness performance of multi-step methods.
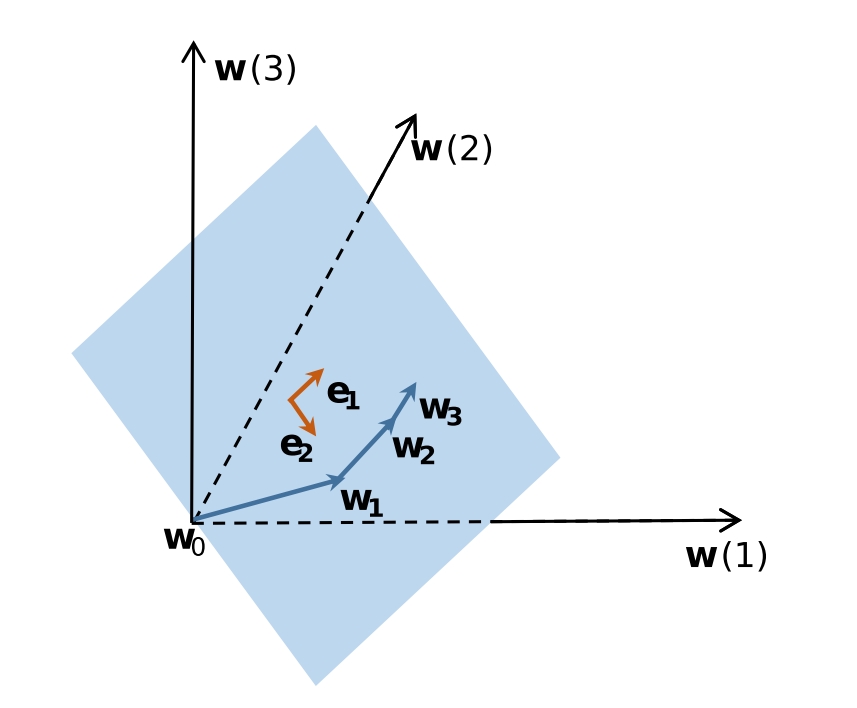
Low Dimensional Trajectory Hypothesis is True: DNNs can be Trained in Tiny Subspaces
Tao Li, Lei Tan, Zhehao Huang, Qinghua Tao, Yipeng Liu, Xiaolin Huang
- This work explores the low-dimensional characteristics of DNN training trajectories and proposes a dimension reduction method for training DNNs within a lower-dimensional subspace. This approach has the potential to reduce training costs and enhance model robustness.
🎖 Honors and Awards
- 2020.07 Shanghai Outstanding Graduates
- 2013.12 First Prize in NOIP (full grades for senior)
📖 Educations
- 2020.09 - 2025.06, Ph.D., Control Science and Engineering, Shanghai Jiao Tong University, Shanghai, China
- 2016.09 - 2020.06, B.Eng., Automation, Shanghai Jiao Tong University, Shanghai, China
💬 Invited Talks
- 2023.03, Trainable Weight Averaging, Huawei 2012 Lab internal talk.
💻 Internships
- 2024.08 - 2025.02, Noah’s Ark Lab, Huawei.
- 2024.05 - 2024.08, DKI Group, Microsoft.
- 2021.09 - 2021.12, Tencent WeChat Group.